by Bernhard Beckert, Jonas Schiffl, Peter H. Schmitt and Mattias Ulbrich
Sorting is a fundamental functionality in libraries, for which efficiency is crucial. Correctness of the highly optimized implementations is often taken for granted. De Gouw et al. have shown that this certainty is deceptive by revealing a bug in the Java Development Kit (JDK) implementation of TimSort.
We have now formally analysed the other implementation of sorting in the JDK standard library: A highly efficient implementation of a dual pivot quicksort algorithm. We were able to deductively prove that the algorithm implementation is correct. However, a loop invariant which is annotated to the source code does not hold.
This post reports on the successful case study in which KeY was applied to a non-trivial real-world implementation of a non-trivial algorithm.
Please find all details in the paper.
Target of the Verification Task
Algorithm
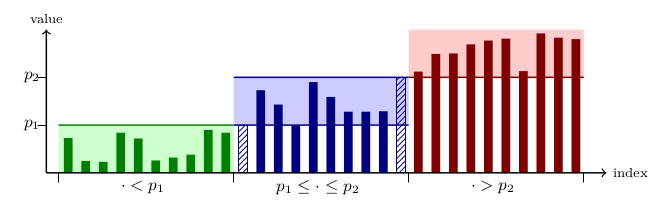
Illustration of a dual pivot partition
While the worst-case runtime complexity of comparison-based sorting algorithms is known to be in the class O(n log(n)), there have been numerous attempts to reduce their “practical” complexity. In 2009, Vladimir Yaroslavskiy suggested a variation of the quicksort algorithm that uses two pivot elements. The figure above exemplarily illustrates the arrangement of the array elements after the partitioning step. The pivot elements are shown as hatched bars. The first part (green in the figure) contains all elements smaller than the smaller pivot element, the middle part (blue) contains all elements between the pivots (inclusively), and the third part (red) consists of all elements greater than the larger pivot. The algorithm proceeds by sorting the three parts recursively by the same principle. Extensive benchmarking led to the adoption of Yaroslavskiy’s Dual Pivot Quicksort implementation as the OpenJDK 7 standard sorting function for primitive data type arrays in 2011. Conclusive explanations for its superior performance appear to be surprisingly hard to find, but evidence points to cache effects. Wild et al. conclude:
“The efficiency of Yaroslavskiy’s algorithm in practice is caused by advanced features of modern processors. In models that assign constant cost contributions to single instructions – i.e., locality of memory accesses and instruction pipelining are ignored – classic Quicksort is more efficient.”
Implementation
We formally analysed the class java.util.DualPivotQuicksort contained both in Oracle’s JDK and in OpenJDK 8.
Like many modern programming languages, the standard library of Java uses a portfolio of various sorting algorithms in different contexts. This class, consisting of more than 3000 lines of code, makes use of no less than four different algorithms: Merge sort, insertion sort, counting sort, and quicksort. For the byte, char, and short data types, counting sort is used. Arrays of other primitive data types are first scanned once to determine whether they consist of a small number of already sorted sequences; if that is the case, merge sort is used, taking advantage of the existing sorted array parts. For arrays with less than 47 entries, insertion sort is used. In all other cases, quicksort is used (e.g., for large integer arrays that are not partially sorted). This “default” option is the subject of our correctness proof.
Verification Task
Toplevel Specification
class DualPivotQuicksort {
// ...
/*@ public normal_behavior
@ ensures (\forall int i; 0 <= i && i < a.length;
@ (\forall int j; 0 < j && j < a.length;
@ i < j ==> a[i] <= a[j]));
@ ensures \seqPerm(\array2seq(a), \old(\array2seq(a)));
@ assignable a[*];
@*/
void sort(int[] a) { ... }
}
This JML specification covers the following aspects of the behaviour of the method sort:
On termination, the array is sorted in increasing order (lines 5–7).
On termination, the array contains a permutation of the initial array content (line 8).
The implementation does not modify any existing memory location except the entries of the array (line 9).
The method always terminates (this is the default for JML if a diverges clause has not been specified).
The method does not throw an exception. This is implied since the contract is declared normal behavior.
Managing the Task
To modularise the problem, we broke down the code into smaller units by refactoring the large sort method into smaller new methods. Besides disentangling the different sorting algorithms, it significantly reduced the complexity of the individual proof obligations. The parts of the code that suggested themselves for method extraction were the partitioning implementation, the initial sorting of the five chosen elements, and several small loops for moving the indices used in the partitioning algorithm. Besides this modularisation into smaller sub-problems, we also reduced complexity by separating three parts of the requirement specification
If the list contains at most 47 Elements, the portfolio engine falls back to insertion sort – in spite of its worse average-case performance – to avoid the comparatively large overhead of quicksort or merge sort. To be more efficient, a variant in which two elements are sorted at a time is used in this case. The challenge to verify the algorithm has been put forth at the VerifyThis competition 2017. Michael Kirsten carried out a verification of the actual implementation using KeY.

One thought on “Proving JDK’s Dual Pivot Quicksort Correct”
Comments are closed.